Separation of Heavy Reasoning and Low-Latency Edge Execution
The physical system was engineered using a custom 3D-printed EEZYbotARM MK2 (4-axis configuration) driven by high-torque MG996R servo motors. To achieve fluid, reliable movements, the workspace uses a dedicated overhead workspace camera calibrated to capture the absolute coordinate grid.
Rather than equipping the robotic arm with a heavy onboard GPU, the architecture implements a strict boundary: **Cloud-based semantic reasoning** (multimodal API calls) takes care of the heavy classification, while the **edge microcontroller (ESP8266)** focuses entirely on low-latency microsecond servo angle execution via high-speed UDP wireless links.

The physical hardware setup showing the overhead camera and the EEZYbotARM ready for multimodal commands.
The Custom Control Dashboard
To monitor and control this distributed system, I developed a custom web dashboard. It bridges manual telemetry overrides and automatic VLA command generation. The dashboard displays the live camera stream overlay, real-time voice command transcription, recognized bounding box locations, and calculated target joint angles (Base, Shoulder, Elbow, Gripper).
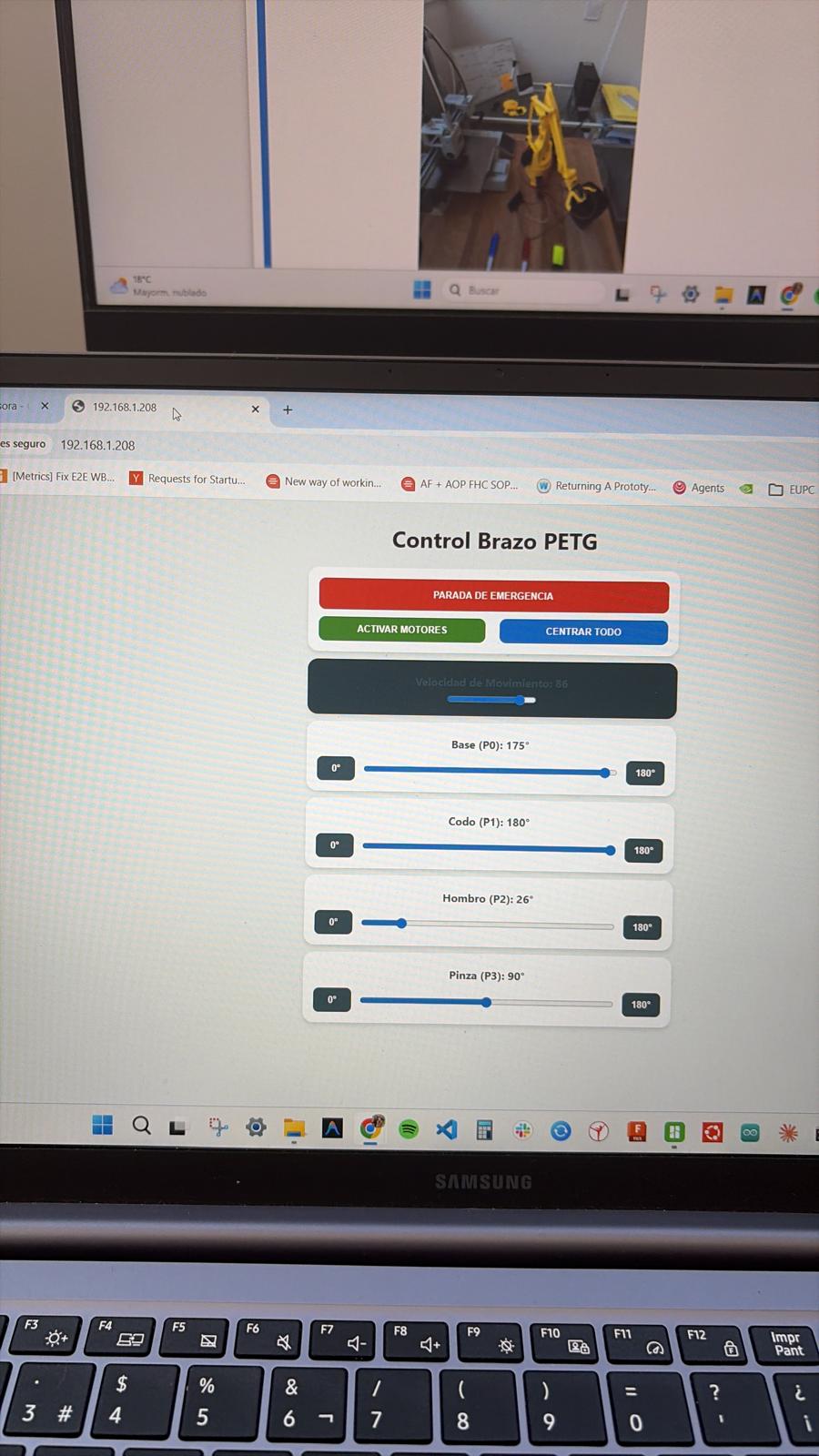
The custom web dashboard used to interface with the Gemini API, displaying the live feed, the recognized text command, and the translated kinematic output.